Introduction
LM-Kit has already enabled .NET developers to integrate advanced text and vision processing into their .NET applications. Today, we’re excited to expand these capabilities even further by introducing on-device speech recognition and audio analysis.
Whether you’re building transcription tools for customer support, multilingual accessibility features, or local voice-controlled interfaces, LM-Kit.NET’s new audio capabilities provide the flexibility and performance to get started quickly, without compromising on privacy.

A New Dimension: Audio Processing Made Easy
LM-Kit.NET now enables .NET developers to leverage cutting-edge audio processing features without relying on cloud providers. Your data stays local, secure, and under your complete control.
Key audio capabilities include:
On-Device AI Transcription: Fast, secure, and accurate speech-to-text directly on your device.
Voice Activity Detection (VAD): Precisely detect speech segments with SileroVAD 5, customizable for specialized use cases. more information about VAD.
Automatic Language Detection: Quickly identify the language from your audio input.
Real-Time Speech Translation: Instantly translate speech into English from over 100 supported languages.
Universal WAV Compatibility: Effortlessly process audio with standard WAV file support.
Batch Processing: Efficiently handle multiple audio streams simultaneously with built-in multithreading.
Powering Speech Recognition with Whisper
LM-Kit integrates Whisper v3 models, offering a balance of accuracy and speed optimized for local execution. We’ve included quantized versions of Whisper models in our catalog to maximize performance on any hardware setup.
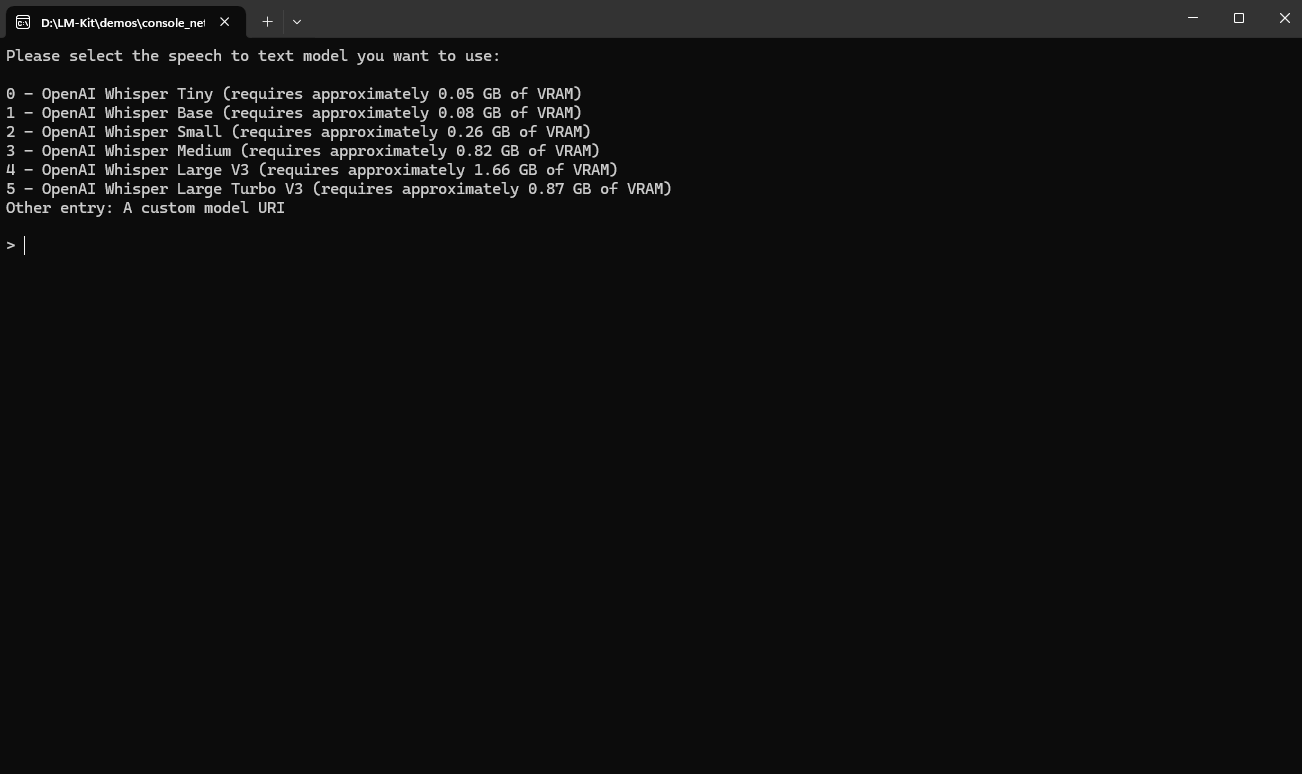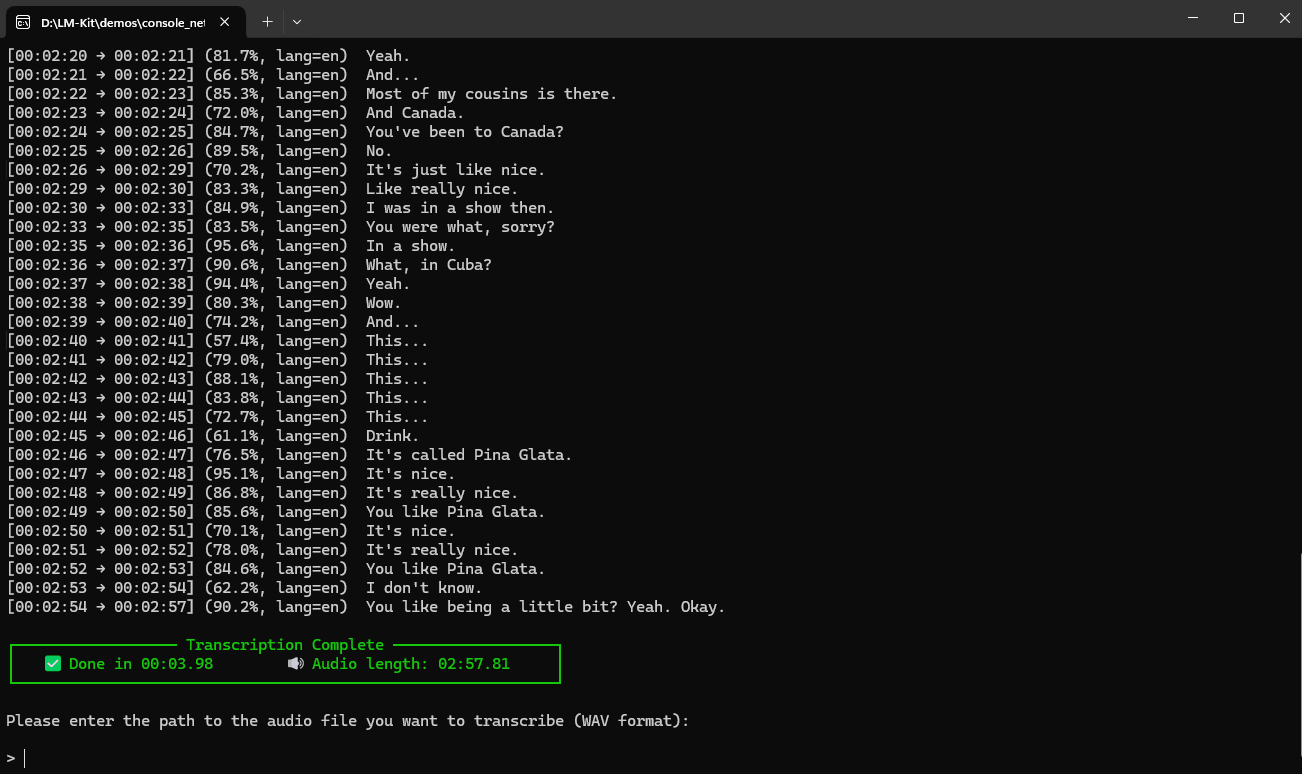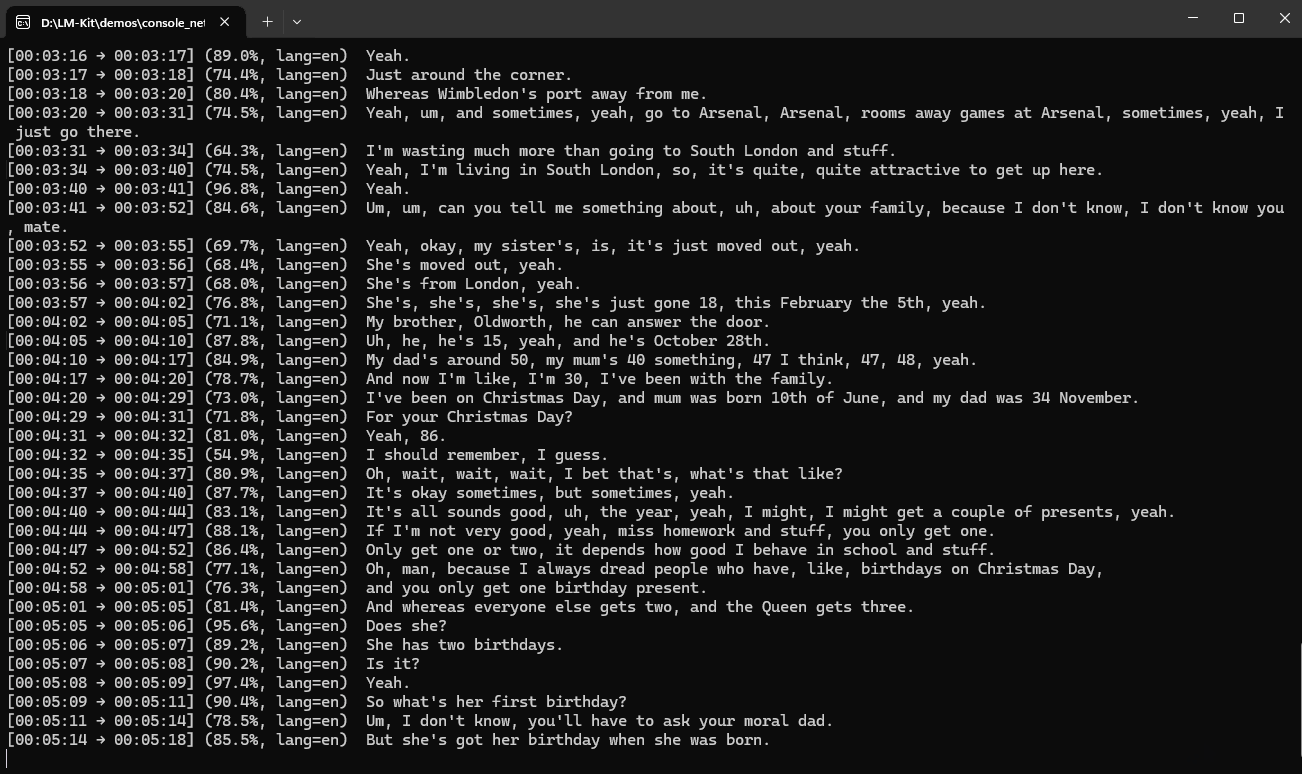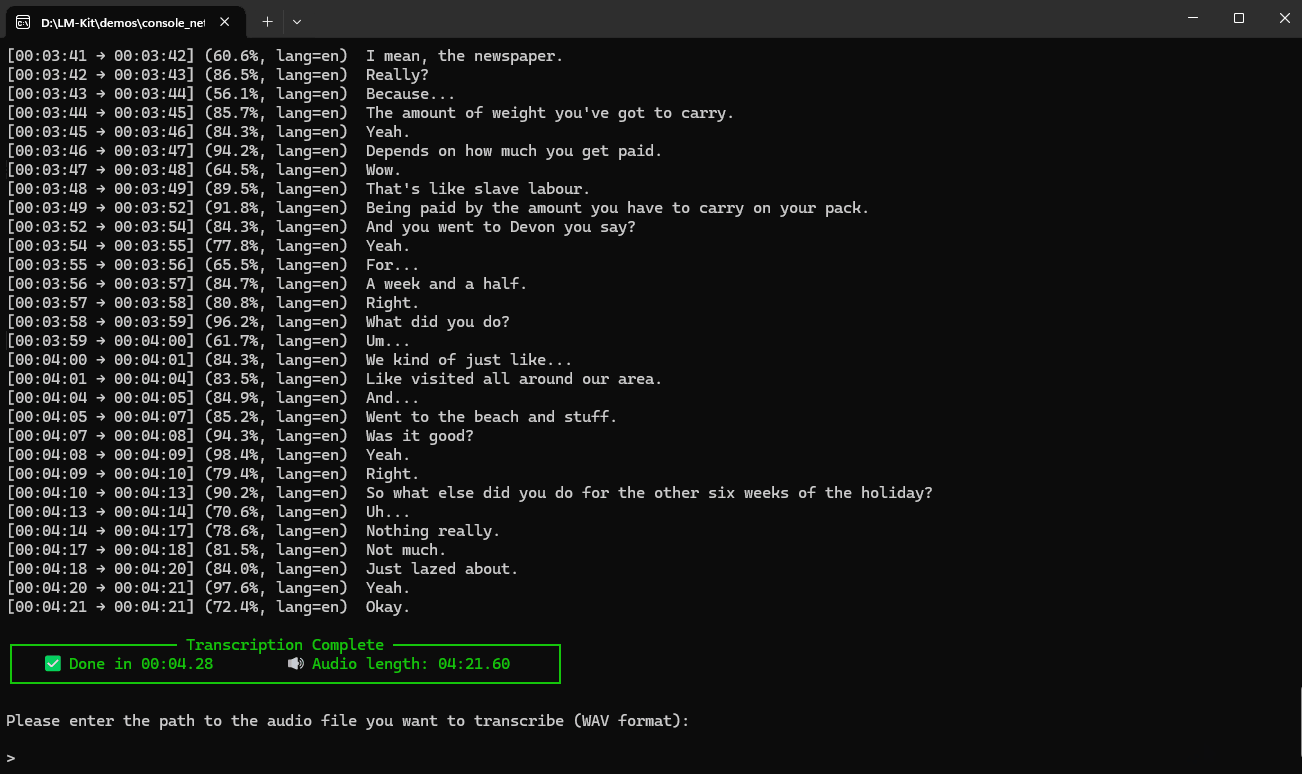
Quick Start: Transcribe Audio with Ease
With LM-Kit, converting audio to text is straightforward. Here are some quick examples:
var model = LM.LoadFromModelID("whisper-large-turbo3");
var wavFile = new WaveFile(@"d:\discussion.wav");
var engine = new SpeechToText(model);
var language = engine.DetectLanguage(wavFile);
Console.WriteLine($"Detected language: {language}");
var model = LM.LoadFromModelID("whisper-large-turbo3");
var wavFile = new WaveFile(@"d:\discussion.wav");
var engine = new SpeechToText(model);
engine.OnNewSegment += (sender, e) => Console.WriteLine(e.Segment);
var transcription = engine.Transcribe(wavFile);
var model = LM.LoadFromModelID("whisper-large3");
var wavFile = new WaveFile(@"d:\discussion.wav");
SpeechToText engine = new(model)
{
Mode = SpeechToText.SpeechToTextMode.Translation
};
engine.OnNewSegment += (sender, e) => Console.WriteLine(e.Segment);
var transcription = engine.Transcribe(wavFile);
Try It Yourself – No Registration Required
Curious to see how it works? Check out our demo repository:
👉 LM-Kit.NET Speech-to-Text Demo Repository
Download, run the example, and experience powerful speech-to-text locally, completely registration-free.
What's Next?
We’re continuously enhancing our speech processing capabilities. Upcoming features include:
Real-Time Recognition: Continuous streaming with minimal delay.
Speaker Diarization: Distinguish between multiple speakers in a single recording.
Expanded VAD Logic: Improved speech detection in noisy environments.
More Models: Broader support for open and commercial STT models.
Unleash the Power of Local Speech AI
LM-Kit.NET empowers your applications with state-of-the-art audio processing while preserving your data privacy and control. Upgrade your apps today, and transform audio data into actionable insights effortlessly.