Introduction
In this article, we introduce AgentMemory, the first iteration of a core component within the LM-Kit framework that augments multi-turn conversations by incorporating persistent, long-term memory. Designed for engineers and researchers, AgentMemory not only captures and recalls key conversation details over time but also filters and refines information to optimize agent behavior. By ensuring that your agents retain context across interactions, we enable smarter, more personalized AI experiences. This update incorporates practical insights from customer feedback and ongoing research to enhance real-world application.
Persistent Memory Inspired by Human Cognition
AgentMemory empowers conversational agents to store and recall essential text partitions across diverse memory types: semantic, episodic, and procedural, which can be organized into distinct collections known as DataSources
This design mirrors human cognitive processes, where different forms of memory work in tandem to inform decisions and responses. By drawing inspiration from the way humans recall and integrate past experiences, AgentMemory dynamically injects contextual memory segments into conversations only when they are not already present in the agent’s short-term memory (or KV-Cache), resulting in more coherent and accurate responses.
The system continuously evaluates whether a memory segment should be recalled, ensuring that only the most pertinent context is integrated during a conversation and preventing redundancy by checking if the information is already available.

Seamless Integration with Multi-Turn Conversations
A key strength of AgentMemory lies in its tight integration with the multi-turn conversation system. When engaged in a dialogue, the system automatically leverages its persistent memory to enrich responses with relevant contextual details. This integration is facilitated through an event-driven approach that notifies subscribers when a memory partition is recalled.
MemoryRecall Event Capabilities
The MemoryRecall event is central to this integration, providing extensive capabilities to tailor and control the memory recall process:
-
Inspection of Recalled Content
Subscribers receive detailed information about the recalled memory partition. This includes:
- Memory Collection Identifier: The source collection from which the memory segment originates.
- Memory Text: The actual content of the recalled memory.
- Unique Memory Identifier: A unique identifier corresponding to the specific memory section.
- Associated Metadata: Optional metadata that may provide further context about the memory partition.
- Memory Type Information: Exposes the type of memory associated with the recalled section, which may be semantic, episodic, or procedural.
-
Dynamic Customization
Beyond inspection, subscribers can modify how the recalled memory is integrated:
- Optional Prefix: Developers can assign a custom prefix that is prepended to the recalled memory content. This enables contextual cues or formatting adjustments before the memory is merged with the ongoing conversation.
- Cancellation of Memory Injection: If the recalled content is deemed irrelevant or potentially disruptive, subscribers can cancel its integration by setting a dedicated flag.
-
Enhanced Debugging and Logging
The event mechanism supports detailed logging and analysis of memory recalls. Developers can track when and why a particular memory segment was recalled, assess its relevance, and make adjustments to the recall criteria as needed.
MemoryRecall event prototype:
namespace LMKit.TextGeneration.Events
{
public class MemoryRecallEventArgs : EventArgs
{
public string MemoryCollection { get; }
public string MemoryText { get; }
public string MemoryId { get; }
public MetadataCollection Metadata { get; }
public string Prefix { get; set; }
public bool Cancel { get; set; }
public MemoryType MemoryType { get; }
}
}
Customizing Memory Recall with Data Filtering
Complementing the dynamic recall process is the DataFilter class, which allows developers to further tailor the memory recall process. DataFilter provides delegate functions that determine which memory collections (DataSources) and individual memory segments (Sections) should be excluded during recall.
How DataFilter Works
-
1- DataSource Filter
A delegate function that evaluates entire memory collections. If the function returns true for a given DataSource, that collection is skipped during the recall process. This feature is useful for excluding outdated or contextually irrelevant collections.
-
2- Section Filter
A delegate function that applies to individual memory segments, allowing fine-grained control over which sections are considered. Developers can implement custom logic based on relevance, sensitivity, or domain-specific criteria.
Benefits and Use Cases
-
1- Domain-Specific Tailoring
In specialized applications such as customer support or technical troubleshooting, DataFilter ensures that only the most pertinent information is recalled by filtering out data that might lead to incorrect or off-topic responses.
-
2- Content Moderation
In environments with strict compliance or privacy requirements, DataFilter helps exclude memory segments that contain sensitive or regulated content.
-
3- Optimized Response Quality
By filtering out noise and irrelevant data, the overall recall mechanism becomes more efficient, delivering more precise and contextually appropriate responses.
Interactive Memory-Enhanced Chatbot Example
This demo features a chatbot enhanced with persistent memory, delivering clear, concise, and factual insights about ACMEE Company’s ideal customer profile.
The console application integrates AgentMemory into a multi-turn conversational agent that uses the efficient Alibaba Qwen 2.5 Instruct 0.5B model, a Small Language Model with only 0.5 billion parameters.
This demonstration shows that advanced memory capabilities can operate effectively on low-cost CPU devices. The complete project is available for download on the LM-Kit GitHub repository.
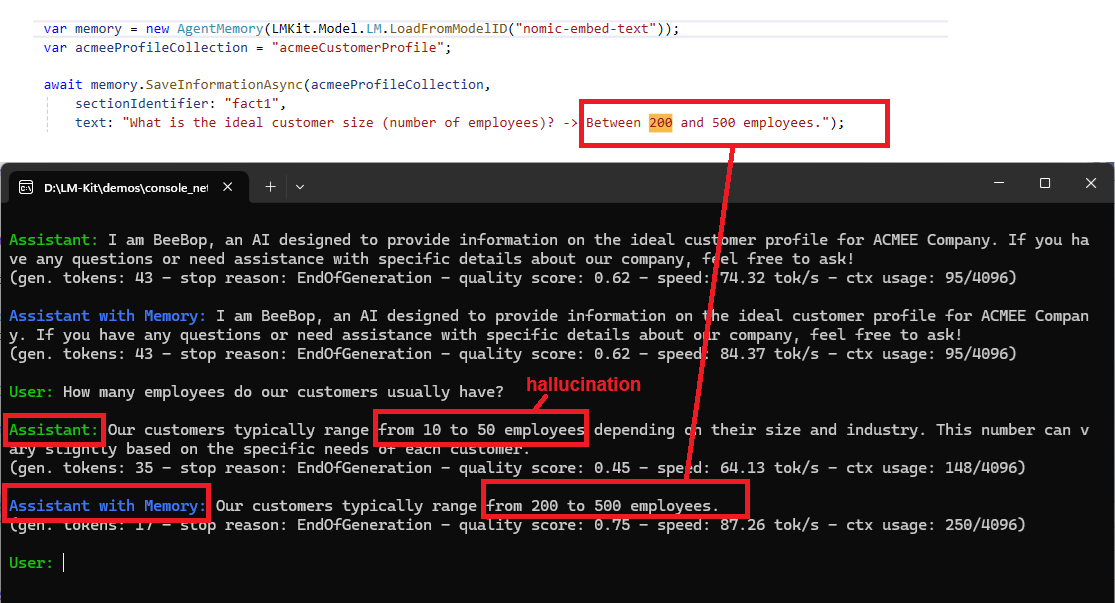
Loading the Model and Memory
Before starting the conversation, the application loads both the language model and persistent memory. The MemoryBuilder.Generate() method checks for a serialized memory file (memory.bin):
-
If the file exists:
The method deserializes the file using the embedding model (here, nomic-embed-text ), restoring previously stored facts.
-
If the file does not exist:
A new memory instance is created and populated with essential facts about Acmee’s ideal customer profile using the asynchronous
SaveInformationAsync()method. Once populated, the memory is serialized tomemory.binfor reuse in subsequent sessions.
// Define the data source identifier for Acmee's customer profile information.
var acmeeProfileCollection = "acmeeCustomerProfile";
// Save a fact about the ideal customer size.
await memory.SaveInformationAsync(
dataSourceIdentifier: acmeeProfileCollection,
text: "What is the ideal customer size (number of employees)? -> Between 200 and 500 employees.",
sectionIdentifier: "fact1"
);
// Save a fact about the typical annual revenue of the ideal customer.
await memory.SaveInformationAsync(
dataSourceIdentifier: acmeeProfileCollection,
text: "What is the typical annual revenue of the ideal customer? -> $20 million to $200 million.",
sectionIdentifier: "fact2"
);
// Save a fact about the industries where Acmee’s ideal customers are found.
await memory.SaveInformationAsync(
dataSourceIdentifier: acmeeProfileCollection,
text: "In which industries are Acmee’s ideal customers primarily found? -> High-tech sectors such as software development, IT services, and digital media.",
sectionIdentifier: "fact3"
);
//… other facts are subsequently loaded.
Parameter Breakdown:
- dataSourceIdentifier: A unique string identifying the memory collection (e.g., “acmeeCustomerProfile”).
- text: The text content that is stored—detailing specific attributes of Acmee’s ideal customer.
- sectionIdentifier: A unique identifier for this piece of information.
- additionalMetadata (optional): Additional metadata that can provide extra context (not used in this snippet).
- cancellationToken (optional): Allows cancellation of the save operation if needed.
Configuring Chatbot Instances
Two conversational agents are configured. One operates without memory integration, while the other is enhanced with persistent memory. Both agents are set with a context size of 4096 tokens and use a greedy decoding strategy:
MultiTurnConversation chat = new MultiTurnConversation(model, contextSize: 4096)
{
MaximumCompletionTokens = 1000,
SamplingMode = new GreedyDecoding(),
SystemPrompt = "You are BeeBop, our agent dedicated to providing information about the ideal customer profile of ACMEE Company. Provide clear and concise answers and include only factual content."
};
MultiTurnConversation chatMemory = new MultiTurnConversation(model, contextSize: 4096)
{
MaximumCompletionTokens = 1000,
SamplingMode = new GreedyDecoding(),
SystemPrompt = "You are BeeBop, our agent dedicated to providing information about the ideal customer profile of ACMEE Company. Provide clear and concise answers and include only factual content.",
Memory = memory
};
chatMemory.MemoryRecall += (sender, e) =>
{
Debug.WriteLine("Memory recall event triggered with content: " + e.MemoryText);
};
Interactive Conversation and Example Scenarios
Example 1
User Prompt:
How many employees do our customers usually have?
Our customers typically range from 10 to 50 employees. This number can vary depending on the specific needs and size of the organization.
(gen. tokens: 30 - stop reason: EndOfGeneration - quality score: 0.52 - speed: 153 tok/s - ctx usage: 136/4096)
Memory-Enhanced Agent Response:
Our customers typically range from 200 to 500 employees.
(gen. tokens: 17 - stop reason: EndOfGeneration - quality score: 0.76 - speed: 160.99 tok/s - ctx usage: 243/4096)
Memory recall event triggered with content: What is the ideal customer size (number of employees)? -> Between 200 and 500 employees.
Memory recall event triggered with content: What is the typical annual revenue of the ideal customer? -> $20 million to $200 million.
Memory recall event triggered with content: What is the typical size of an internal IT team? -> Generally, between 20 and 100 dedicated IT professionals.
Example 2
User Prompt:
(gen. tokens: 45 - stop reason: EndOfGeneration - quality score: 0.54 - speed: 102.11 tok/s - ctx usage: 197/4096)
Memory-Enhanced Agent Response:
Acmee’s ideal customers work in high-tech sectors such as software development, IT services, and digital media
(gen. tokens: 24 - stop reason: EndOfGeneration - quality score: 0.75 - speed: 162.87 tok/s - ctx usage: 407/4096)
Memory recall event triggered with content: In which industries are Acmee’s ideal customers primarily found? -> High-tech sectors such as software development, IT services, and digital media.
Memory recall event triggered with content: What is a key operational priority for these companies? -> Achieving rapid yet deliberate digital transformation by integrating AI and automation.
Memory recall event triggered with content: What do these companies view as the future of digital technology? -> As a critical driver of growth, innovation, and competitive differentiation.
Quick Summary
This example uses the efficient Alibaba Qwen 2.5 Instruct 0.5B model to demonstrate how AgentMemory boosts multi-turn conversational accuracy and context awareness, reducing hallucinations. Check out the full project on the LM-Kit GitHub repository.
Use Cases and Future Directions
We believe AgentMemory may help improve intelligent systems by providing persistent, context aware memory that works reliably even on low cost devices. Its practical applications in chatbot interactions and memory management form a solid foundation for further improvements, and we look forward to refining planning, tool integration, and task delegation to support more autonomous agents.
Practical Applications:
- Context-Enriched Chatbots: Leveraging persistent memory allows chatbots to maintain a coherent context over extended dialogues, significantly reducing the occurrence of hallucinated responses.
- Resource-Constrained Environments: AgentMemory demonstrates that effective memory recall can be achieved even on low-cost CPU devices, especially when paired with a tiny Small Language Model (SLM).
- Custom Memory Management: The combination of dynamic memory recall and DataFilter customization empowers organizations to align memory usage with domain-specific requirements and compliance policies.
Looking Ahead
This first iteration of AgentMemory establishes a solid foundation for future enhancements. We are actively developing an Autonomous Agent class that will integrate AgentMemory with additional core components to enable sophisticated, agentic workflows. The upcoming Autonomous Agent will encompass:
- Persona and Instruction: Already implemented to define the agent’s identity and operational guidelines.
- Memory: Harnessing AgentMemory for robust, context-aware recall.
- Planning: (Under development) Allowing agents to strategize and plan actions based on evolving conversation contexts.
- Tools: (Under development) Integrating external utilities and APIs to extend the agent’s functional capabilities.
- Delegation: (Under development) Empowering agents to autonomously delegate tasks and manage subtasks.
Conclusion
The introduction of AgentMemory marks a significant advancement in the LM-Kit framework, offering a robust solution for persistent memory storage and contextual recall. By mirroring human cognition, in which various forms of memory collaborate to inform decisions, AgentMemory delivers a flexible and powerful foundation for building intelligent, context-aware conversational agents. Its seamless integration with multi-turn conversations, enhanced by the dynamic MemoryRecall event and the customizable DataFilter, ensures that only the most relevant context shapes the dialogue.
As we look forward, the forthcoming Autonomous Agent class promises to further expand these capabilities, paving the way for complex, self-governing agent workflows. We invite you to explore AgentMemory, integrate it into your systems, and contribute your feedback as we continue to evolve this exciting technology.